Demonstration of Research
Multichannel blind audio source separation based on harmonic vector analysis (HVA)
This is a demonstration of the paper entitled "Determined BSS based on time-frequency masking and its application to harmonic vector analysis."
Blind audio source separation (BSS) is a technique to estimate individual audio sources in an observed mixture signal, where the mixing system (spatial locations of microphones and sources) is unknown. When the number of sources is equal to the number of microphones, this problem is called "determined BSS." BSS can be used as a frontend processing of almost all audio applications including automatic speech recognition, hearing-aid system, automatic music transcription, and so on.
The most successful algorithms in the determined BSS history are independent vector analysis (IVA) and independent low-rank matrix analysis (ILRMA) proposed in 2006 and 2016, respectively (see here for IVA and ILRMA). These algorithms utilize a source model, an assumption of time-frequency structure for each source. In IVA, frequency vector model is assumed to represent the time-varying activation of each source. In ILRMA, the low-rank time-frequency model is assumed to represent repetition of similar spectral patterns (timbres).
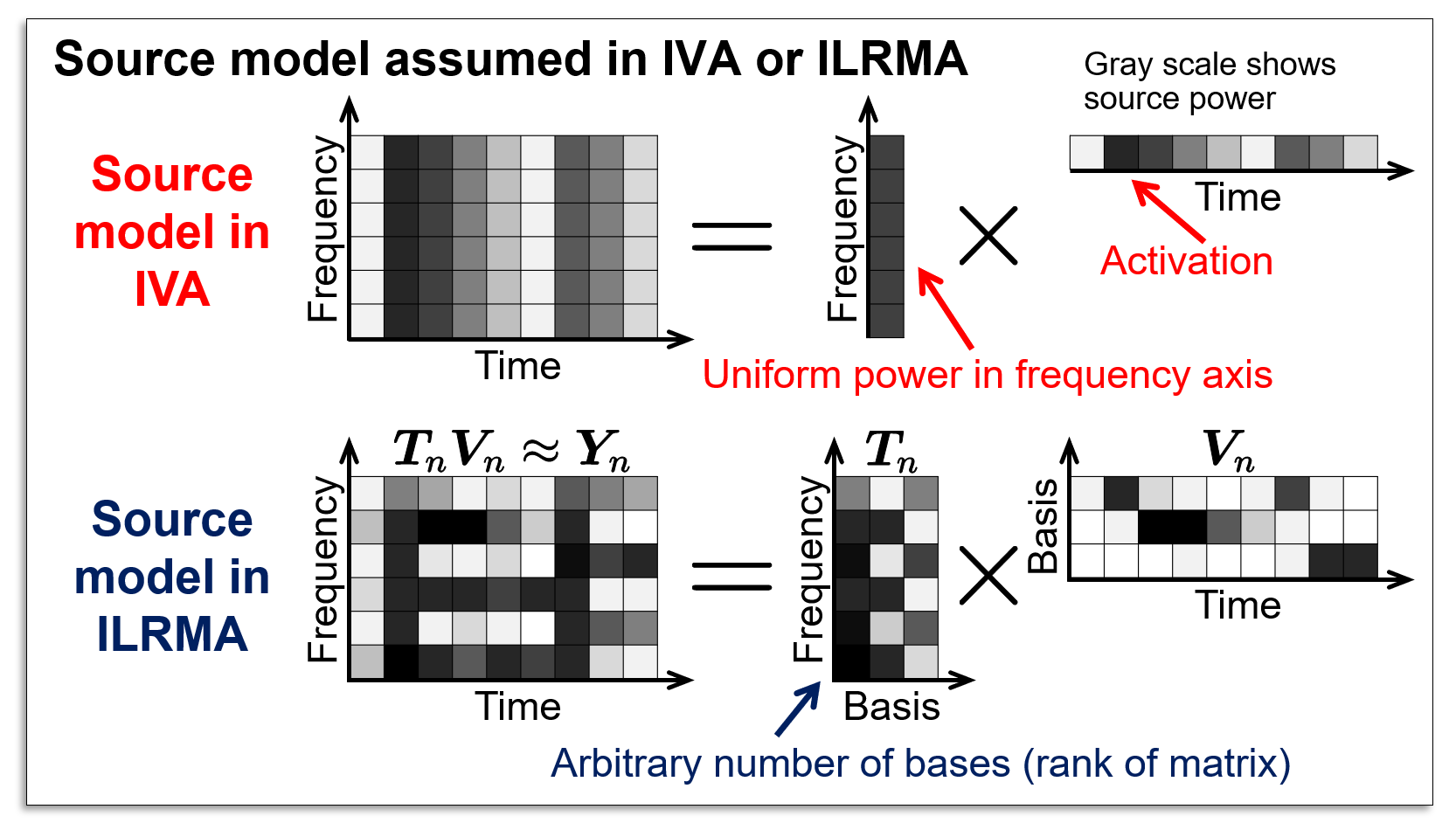
An accurate source model improves the performance of BSS. For seeking more effective source models, we proposed time-frequency-masking-based determined BSS (TFMBSS), where any kind of time-frequency masks can be utilized as a source model in a plug-and-play manner. For example, TFMBSS based on harmonic/percussive sound separation (HPSS) was proposed by incorporating a single-channel HPSS algorithm.
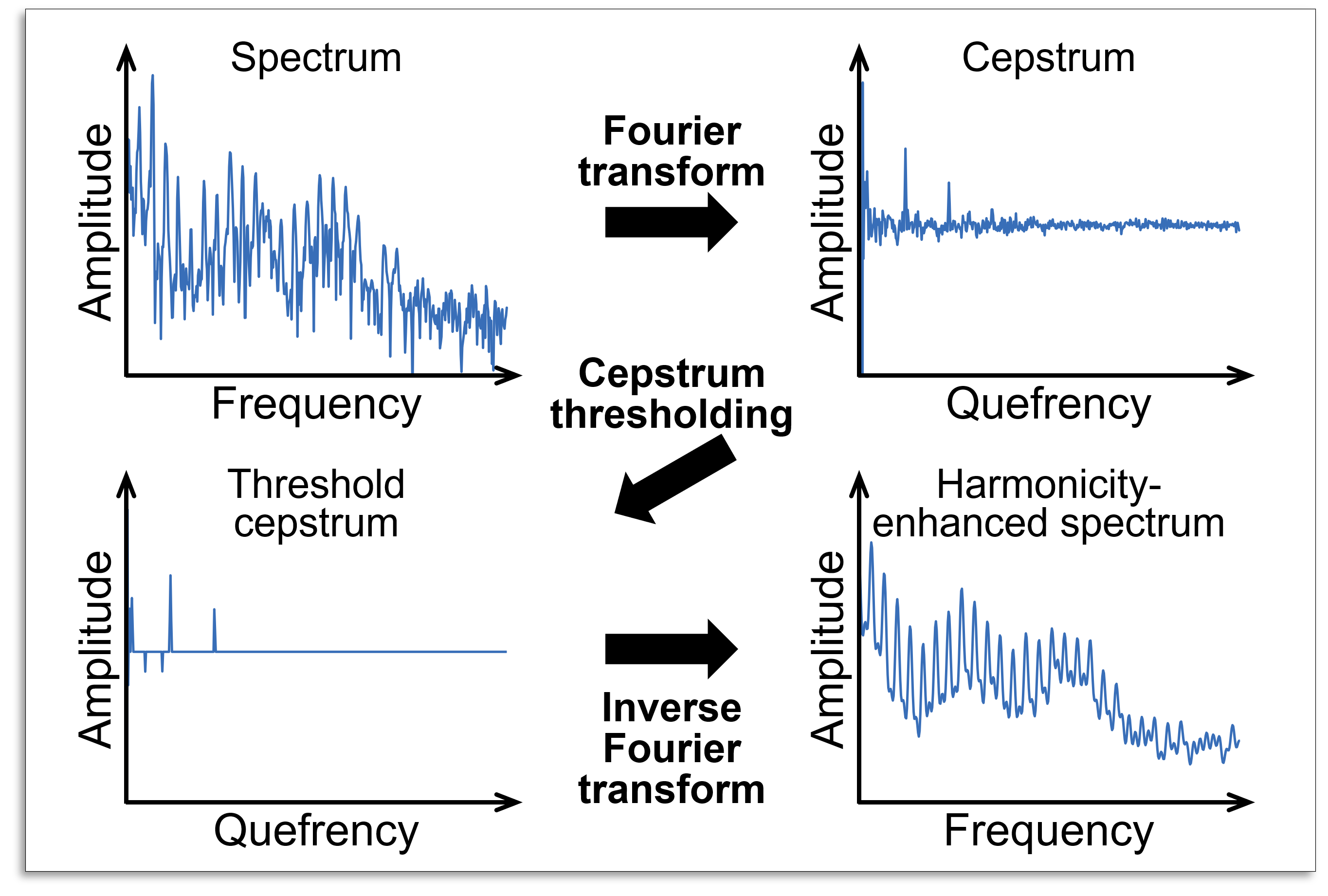
Almost all audio sources including speech and music have a harmonic structure: the fundamental frequency and its overtones are generated. On the basis of this basic principle, we proposed harmonic vector analysis (HVA). In HVA, a time-frequency mask in TFMBSS is calculated by enhancing harmonic structures of each source. The fig. shows typical example of a voiced speech spectrum and its enhancement by the cepstrum thresholding. The log-amplitude spectrum of voiced speech (top-left) is converted to cepstrum (top-right) by the Fourier transform. By thresholding the cepstrum coefficients (bottom-left) and taking the inverse Fourier transform, the enhanced version of the log-amplitude spectrum is obtained (bottom-right).
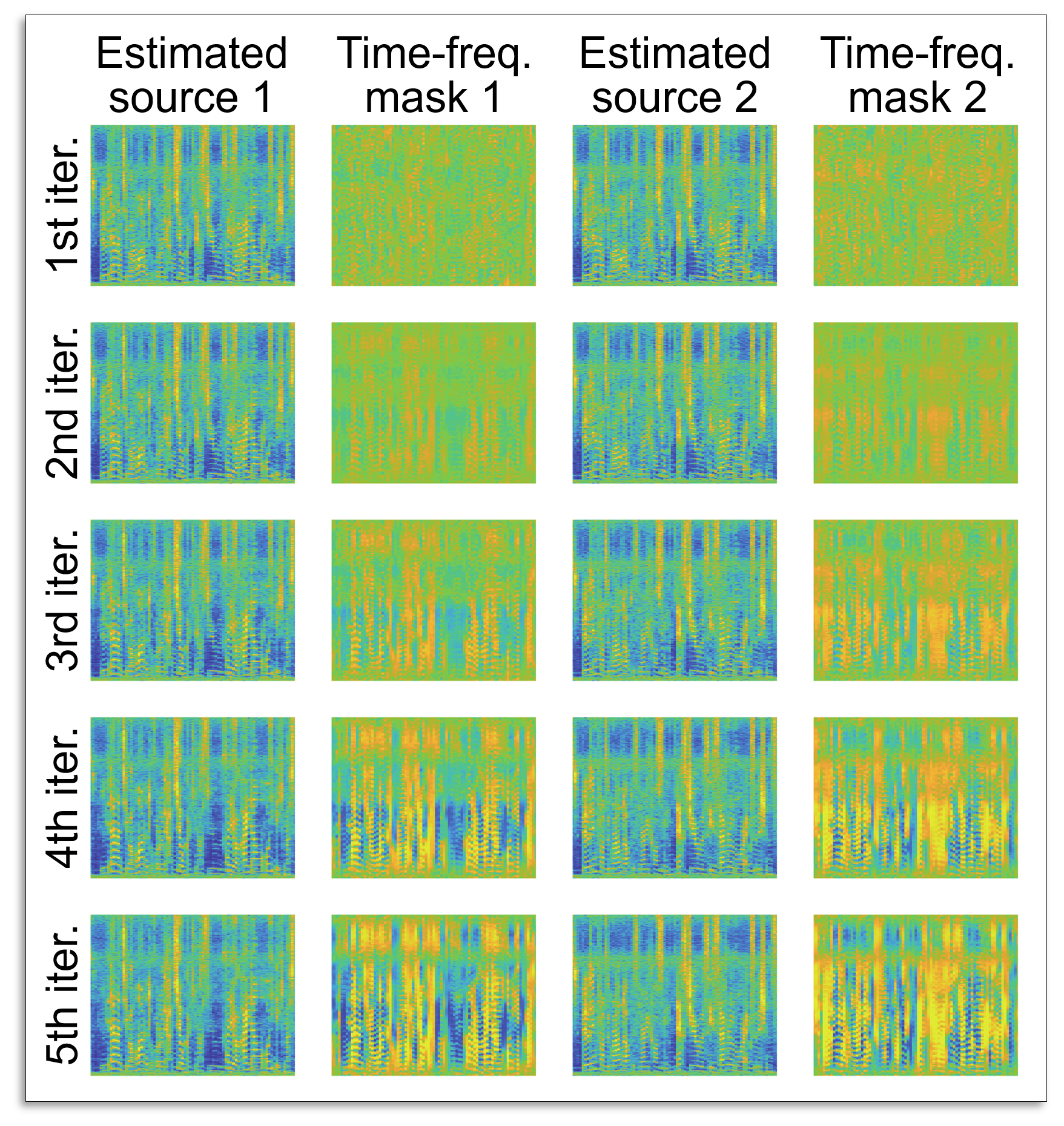
In the parameter optimization of HVA, the harmonic structure of each estimated source is iteratively enhanced by the above-mentioned operation. Thus, the components that have a harmonic structure are automatically grouped as the same source, and the sources are gradually separated during the iterative parameter optimization. This process is demonstrated in fig.
The fig. shows (whitened) spectrograms and masks for the first five iterations of HVA in two-source determined BSS case. We can confirm that the time-frequency masks for each source are drastically changed to have the harmonic structure (striped patterns in the time-frequency domain). As a result, the estimated sources are approaching to their original time-frequency signals.
The following demonstration separates the speech source signal by IVA, ILRMA, and HVA. The two-channel mixture signal was used as an observed signal in this demonstration, where this signal is recorded in the room with 130 ms reverberation time.
The signals were obtained from SiSEC and used only for an academic research purpose.
Live-recorded two-channel mixture with two speech sources
Input signal "dev1_female4_liverec_130ms_5cm_sim"
Separation by IVA
Estimated signal 2
Separation by ILRMA
Estimated signal 2
Separation by HVA
Estimated signal 2
Input signal "dev1_male4_liverec_130ms_5cm_sim"
Separation by IVA
Estimated signal 2
Separation by ILRMA
Estimated signal 2
Separation by HVA
Estimated signal 2
Source code
References
- IVA
-
- T. Kim, T. Eltoft, and T.-W. Lee, "Independent vector analysis: An extension of ICA to multivariate components," in Proc. Int. Conf. Independent Compon. Anal. Blind Source Separation, pp. 165–172, 2006.
- A. Hiroe, "Solution of permutation problem in frequency domain ICA using multivariate probability density functions," in Proc. Int. Conf. Independent Compon. Anal. Blind Source Separation, pp. 601–608, 2006.
- T. Kim, H. T. Attias, S.-Y. Lee, and T.-W. Lee, "Blind source separation exploiting higher-order frequency dependencies," IEEE Trans. Audio, Speech, Lang. Process., vol. 15, no. 1, pp. 70–79, 2007.
- Stable and fast optimization called iterative projection (IP) in IVA
-
- N. Ono, "Stable and fast update rules for independent vector analysis based on auxiliary function technique," in Proc. IEEE Workshop on App. of Signal Process. to Audio and Acoust., pp. 189–192, 2011.
- ILRMA
-
- D. Kitamura, N. Ono, H. Sawada, H. Kameoka, and H. Saruwatari, "Efficient multichannel nonnegative matrix factorization exploiting rank-1 spatial model," in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., pp. 276–280, 2015.
- D. Kitamura, N. Ono, H. Sawada, H. Kameoka, and H. Saruwatari, "Determined blind source separation unifying independent vector analysis and nonnegative matrix factorization," IEEE/ACM Trans. Audio, Speech, and Lang. Process., vol. 24, no. 9, pp. 1626–1641, 2016.
- D. Kitamura, N. Ono, H. Sawada, H. Kameoka, and H. Saruwatari, "Determined blind source separation with independent low-rank matrix analysis," Audio Source Separation, S. Makino, Ed. (Springer, Cham, 2018), pp. 125–155.
- TFMBSS
-
- K. Yatabe and D. Kitamura, "Determined blind source separation via proximal splitting algorithm," in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., pp. 776–780, 2018.
- K. Yatabe and D. Kitamura, "Time-frequency-masking-based determined BSS with application to sparse IVA," in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., pp. 715–719, 2019.
- K. Yatabe and D. Kitamura, "Determined BSS based on time-frequency masking and its application to harmonic vector analysis," IEEE/ACM Trans. Audio, Speech, and Lang. Process., vol. 29, pp. 1609–1625, 2021.
- HPSS-based TFMBSS
-
- S. Oyabu, D. Kitamura, and K. Yatabe, "Linear multichannel blind source separation based on time-frequency mask obtained by harmonic/percussive sound separation," in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., pp. 201–20, 2021.
- HVA
-
- K. Yatabe and D. Kitamura, "Determined BSS based on time-frequency masking and its application to harmonic vector analysis," IEEE/ACM Trans. Audio, Speech, and Lang. Process., vol. 29, pp. 1609–1625, 2021.