Demonstration of Research
Multichannel supervised audio source separation based on independent deeply learned matrix analysis (IDLMA)
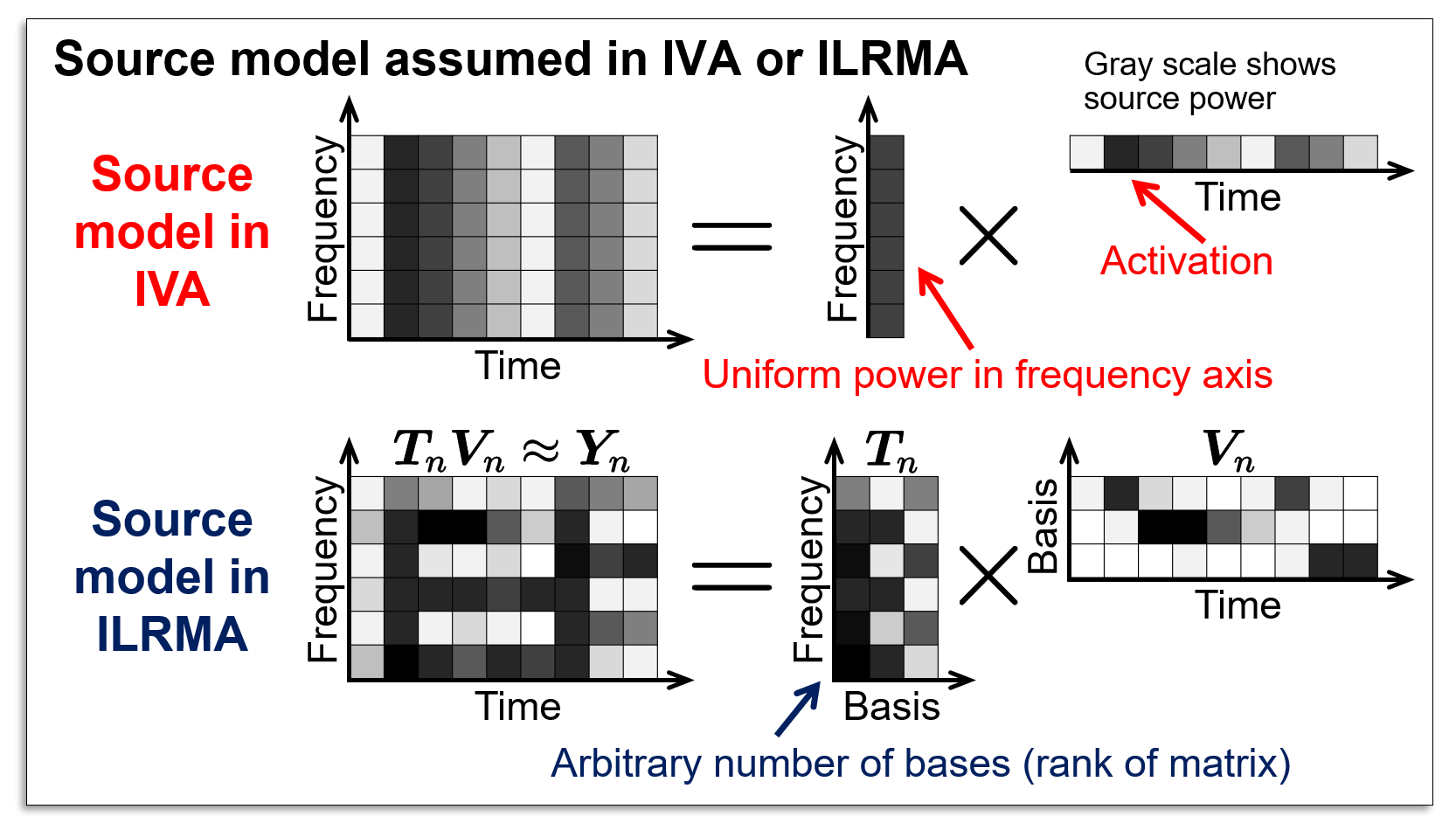
In independence-based blind audio source separation, such as independent component analysis (ICA), we must solve the permutation problem (see here for ICA and the permutation problem), which is an alignment of estimated components along with frequency. To solve this problem, independent vector analysis (IVA) and independent low-rank matrix analysis (ILRMA) were proposed, where IVA assumes co-occurrence of frequency components of sources and ILRMA assumes both co-occurrence of time-frequency components and a low-rank structure of sources.
In these methods, blind source separation can be achieved without encountering the permutation problem if the assumed source model fits to the target sources.
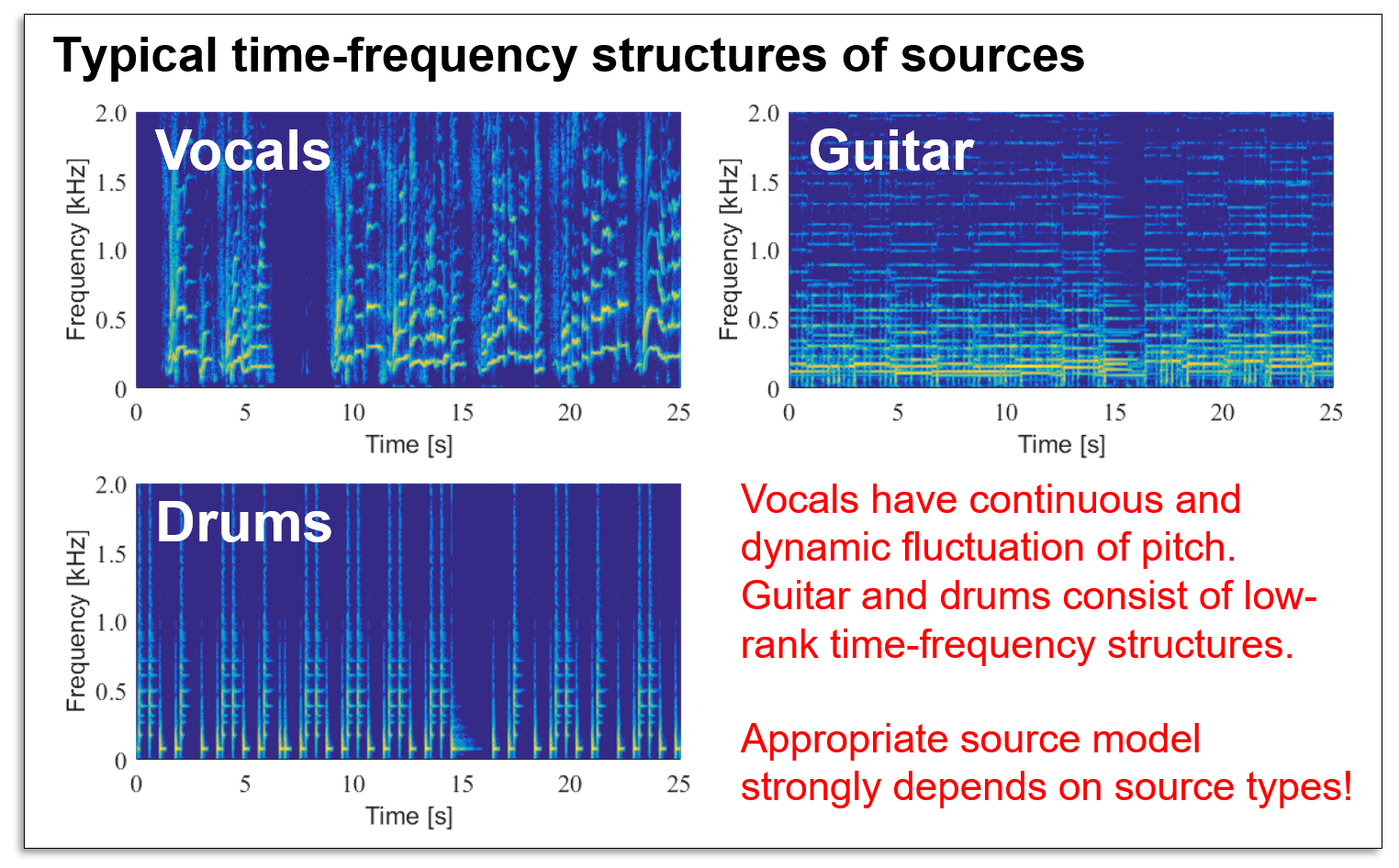
However, a time-frequency structure strongly depends on the type of sources. For example, vocals have complex (not low-rank) structures because of continuously and dynamically fluctuating pitches, and ILRMA is not suitable for vocal separation. Guitars and drums include the same timbre patterns many times, thus they have a low-rank time-frequency structure and ILRMA can separate these sources with high accuracy.
It is almost impossible to find a valid source model for all the sources. Moreover, since the criterion for "suitability of source model" cannot be defined well, users must choose the appropriate source model based on their knowledge or experiences.
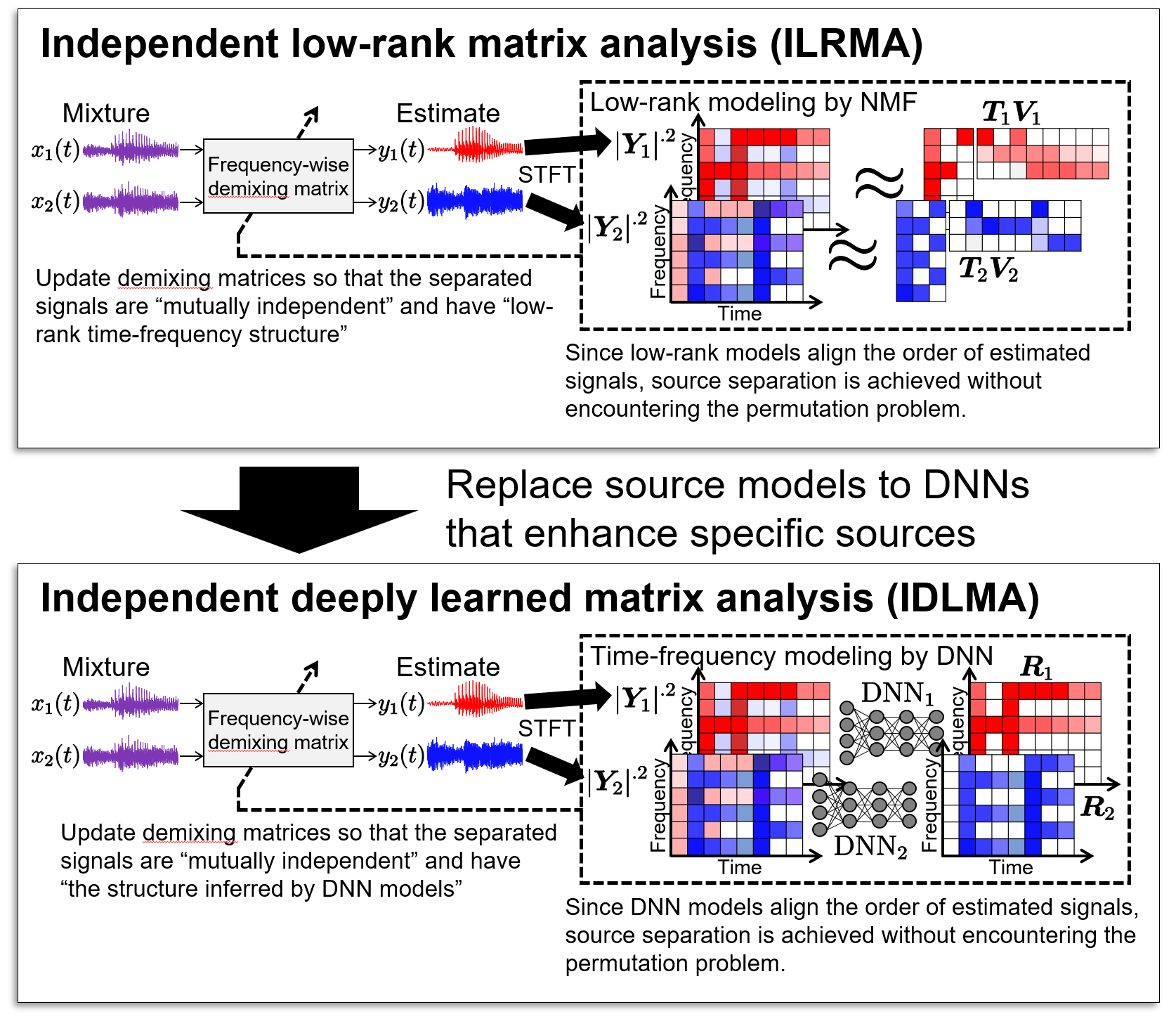
If we automatically obtain a suitable source model from a dataset of various sources, the separation performance will further improve. In practice, we first prepare 30 hours of solo-recorded vocals and guitar sounds in advance. Then, "the vocal-enhance model" and "the guitar-enhance model" are trained to utilize them as the source model.
These models can be trained by using deep neural networks (DNN), namely, the time-frequency structures of guitars and vocals are captured by DNN. Since DNN is used only for estimating linear time-invariant separation filters (as the same as those in IVA and ILRMA), the separated signal includes less artificial distortion compared with that of single-channel DNN-based separation methods. Also, similar to ILRMA, an efficient optimization algorithm for the demixing matrix called iterative projection (IP) can be utilized to achieve computationally cheap BSS. We call this method "independent low-rank matrix analysis (IDLMA)."
In this demonstration, we compare the performance of IDLMA and its extension, t-IDLMA, where the DNN source models are trained for vocals, bass, and drums using 50 songs. The following four methods are compared: ILRMA, t-ILRMA (extension of ILRMA), Duong+DNN, and DNN+WF, where ILRMA and t-ILRMA are the blind (unsupervised) method. Duong+DNN is a multichannel audio source separation technique that estimates a spatial covariance matrix using the DNN source model. However, Duong+DNN requires a high computational cost (10 times slower than ILRMA). DNN+WF is a single-channel audio source separation technique based on a Wiener filter constructed by DNN outputs. All the music data used in this demonstration were obtained from SiSEC and used only for an academic research purpose.
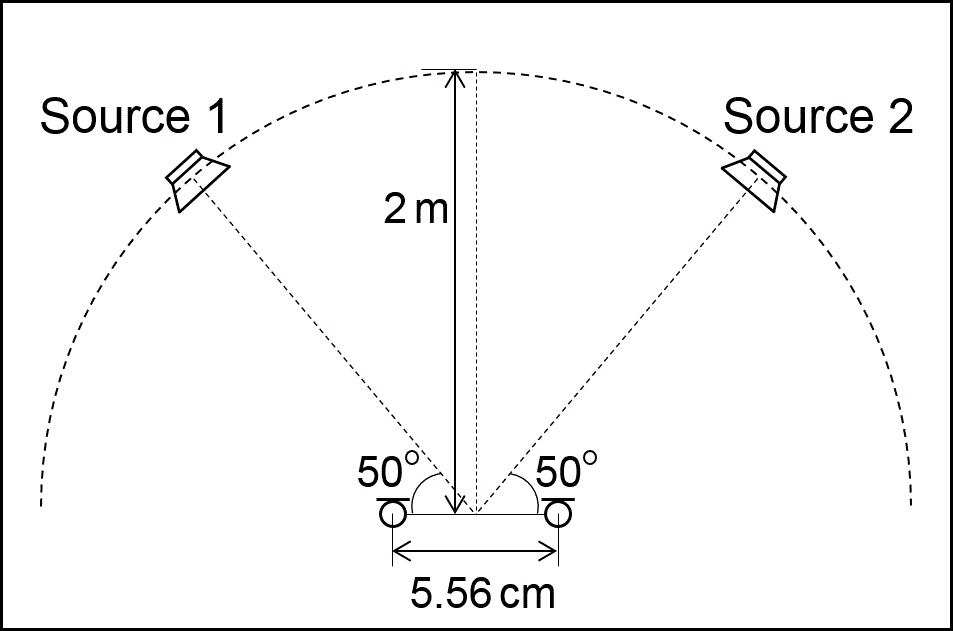
Two-source separation recorded by two-microphone array
Input signal "ANiMAL - Clinic A" (DSD100 001)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "ANiMAL - Rockshow" (DSD100 002)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "Actions - One Minute Smile" (DSD100 003)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "Al James - Schoolboy Facination" (DSD100 004)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "Angela Thomas Wade - Milk Cow Blues" (DSD100 005)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "ANiMAL - Clinic A" (DSD100 001)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "ANiMAL - Rockshow" (DSD100 002)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "Actions - One Minute Smile" (DSD100 003)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "Al James - Schoolboy Facination" (DSD100 004)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
Input signal "Angela Thomas Wade - Milk Cow Blues" (DSD100 005)
Separation by ILRMA
Estimated signal 2 (Vocals)
Separation by t-ILRMA (nu=1000)
Estimated signal 2 (Vocals)
Separation by Duong+DNN
Estimated signal 2 (Vocals)
Separation by DNN+WF
Estimated signal 2 (Vocals)
Separation by IDLMA
Estimated signal 2 (Vocals)
Separation by t-IDLMA (nu=1000)
Estimated signal 2 (Vocals)
References
- IVA
-
- T. Kim, T. Eltoft, and T.-W. Lee, "Independent vector analysis: An extension of ICA to multivariate components," in Proc. Int. Conf. Independent Compon. Anal. Blind Source Separation, pp. 165–172, 2006.
- A. Hiroe, "Solution of permutation problem in frequency domain ICA using multivariate probability density functions," in Proc. Int. Conf. Independent Compon. Anal. Blind Source Separation, pp. 601–608, 2006.
- T. Kim, H. T. Attias, S.-Y. Lee, and T.-W. Lee, "Blind source separation exploiting higher-order frequency dependencies," IEEE Trans. Audio, Speech, Lang. Process., vol. 15, no. 1, pp. 70–79, 2007.
- IP in ICA or IVA
-
- N. Ono and S. Miyabe, "Auxiliary-function-based independent component analysis for super-Gaussian sources," in Proc. Int. Conf. Latent Variable Anal. and Signal Separation, pp. 165–172, 2010.
- N. Ono, "Stable and fast update rules for independent vector analysis based on auxiliary function technique," in Proc. IEEE Workshop on App. of Signal Process. to Audio and Acoust., pp. 189–192, 2011.
- ILRMA
-
- D. Kitamura, N. Ono, H. Sawada, H. Kameoka, and H. Saruwatari, "Efficient multichannel nonnegative matrix factorization exploiting rank-1 spatial model," in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., pp. 276–280, 2015.
- D. Kitamura, N. Ono, H. Sawada, H. Kameoka, and H. Saruwatari, "Determined blind source separation unifying independent vector analysis and nonnegative matrix factorization," IEEE/ACM Trans. Audio, Speech, and Lang. Process., vol. 24, no. 9, pp. 1626–1641, 2016.
- D. Kitamura, N. Ono, H. Sawada, H. Kameoka and H. Saruwatari, "Determined blind source separation with independent low-rank matrix analysis," Audio Source Separation, S. Makino, Ed. (Springer, Cham, 2018), pp. 125–155.
- t-ILRMA
-
- S. Mogami, D. Kitamura, Y. Mitsui, N. Takamune, H. Saruwatari, and N. Ono, "Independent low-rank matrix analysis based on complex Student's t-distribution for blind audio source separation," Proc. MLSP, 2017.
- D. Kitamura, S. Mogami, Y. Mitsui, N. Takamune, H. Saruwatari, N. Ono, Y. Takahashi, and K. Kondo, "Generalized independent low-rank matrix analysis using heavy-tailed distributions for blind source separation," EURASIP JASP vol. 2018, no. 1, p. 28, 2018.
- Multichannel audio source separation combining spatial covariance model (Duong's model) and DNN (Duong+DNN)
-
- A. A. Nugraha, A. Liutkus, and E. Vincent, "Multichannel audio source separation with deep neural networks," IEEE/ACM Trans. ASLP, vol. 24, no. 9, pp. 1652–1664, 2016.
- A. A. Nugraha, A. Liutkus, and E. Vincent, "Deep neural network based multichannel audio source separation," Audio Source Separation, S. Makino, Ed. (Springer, Cham, 2018), pp. 157–185.
- IDLMA and t-IDLMA
-
- S. Mogami, H. Sumino, D. Kitamura, N. Takamune, S. Takamichi, H. Saruwatari, and N. Ono, "Independent deeply learned matrix analysis for multichannel audio source separation," Proc. EUSIPCO, pp. 1571–1575, 2018.
- N. Makishima, S. Mogami, N. Takamune, D. Kitamura, H. Sumino, S. Takamichi, H. Saruwatari, and N. Ono, "Independent deeply learned matrix analysis for determined audio source separation," IEEE/ACM Trans. ASLP, vol. 27, no. 10, pp. 1601–1615, 2019.